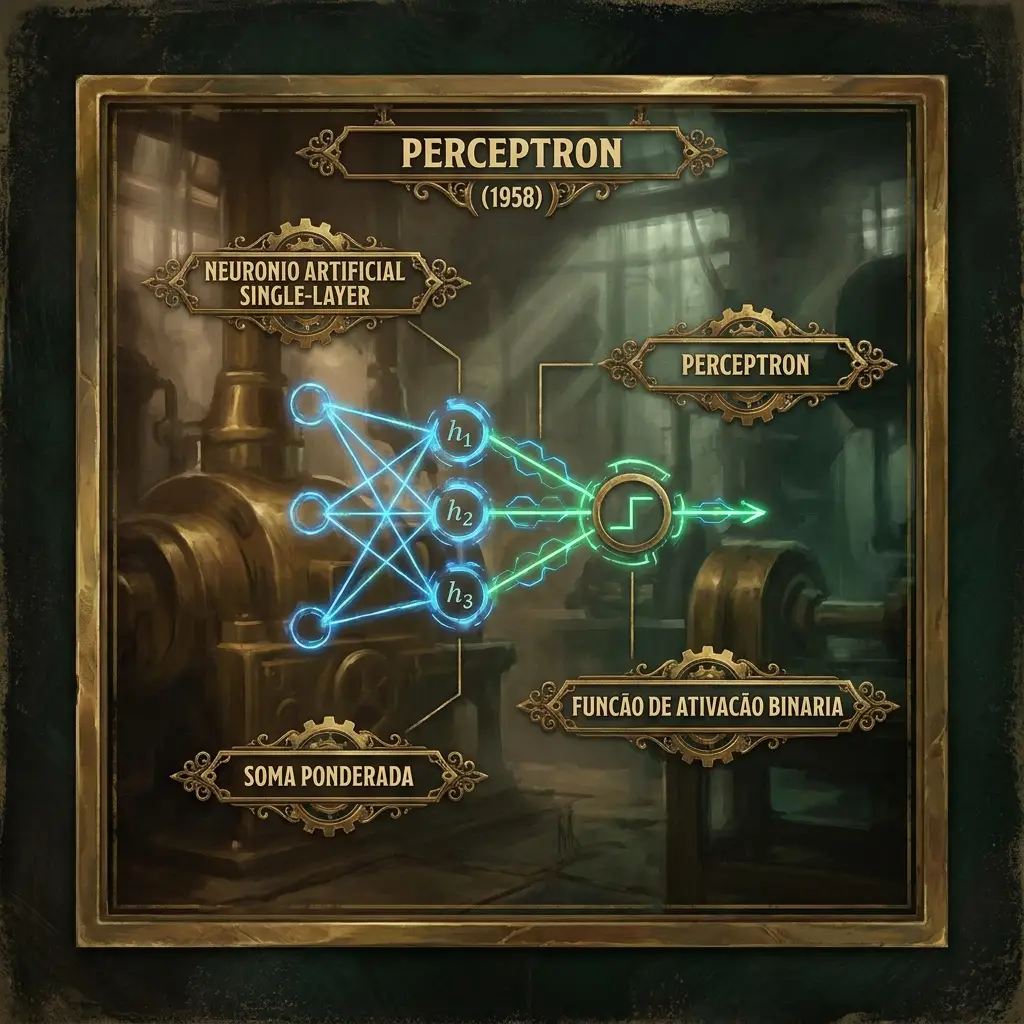
Perceptron
Neurônio artificial single-layer — soma ponderada + função de ativação binária.
O quê
O Perceptron é o primeiro modelo computacional de neurônio artificial com capacidade de aprendizado supervisionado. Proposto por Frank Rosenblatt em 1957–1958 (Cornell Aeronautical Laboratory), implementado primeiro como simulação no IBM 704 e depois como Mark I Perceptron, uma máquina física com 400 fotorreceptores e 512 pesos ajustáveis por potenciômetros eletromecânicos.
A ideia é mínima: o neurônio recebe inputs $x_1, x_2, \dots, x_n$, multiplica cada um por um peso $w_i$, soma, e dispara (output = 1) se a soma cruzar um limiar; caso contrário, fica em silêncio (output = 0). O algoritmo de aprendizado ajusta os pesos quando o output está errado.
O Perceptron sobreviveu a uma controvérsia famosa (Minsky & Papert, 1969) que matou financiamento de redes neurais por uma década — o primeiro AI Winter neural. Voltou nos anos 80 como multi-layer perceptron (MLP) com backpropagation. Hoje, qualquer fully-connected layer em PyTorch é literalmente uma camada de perceptrons.
Como funciona
A unidade
Um perceptron com $n$ inputs computa:
y = step(Σ w_i × x_i + b)Onde:
- $x_i$ são as features de input (binárias no original; reais em formulações modernas).
- $w_i$ são os pesos aprendidos.
- $b$ é o bias (limiar).
stepé a função degrau (Heaviside): 1 se argumento positivo, 0 caso contrário.
Geometricamente: o perceptron define um hiperplano no espaço de features. Pontos de um lado classificam como 1, do outro como 0. É um classificador linear binário.
O algoritmo de aprendizado
Dado um conjunto de treino (x_j, y_j):
1. Inicializar pesos w_i = 0 (ou aleatórios pequenos).
2. Para cada exemplo (x_j, y_j):
- Computar predição ŷ = step(w · x).
- Se ŷ ≠ y: atualizar w_i := w_i + η (y - ŷ) x_i, para todo i.
3. Repetir até nenhuma atualização (convergência).η é a taxa de aprendizado. A atualização tem interpretação geométrica direta: empurra o hiperplano na direção que reduz o erro no exemplo atual.
Rosenblatt provou o Perceptron Convergence Theorem: se os dados são linearmente separáveis, o algoritmo converge em um número finito de passos, independente da inicialização e do $\eta$. Esse foi o primeiro resultado de convergência garantida em aprendizado de máquina.
O Mark I (hardware)
Para impressionar a Office of Naval Research (que financiava o projeto), Rosenblatt construiu o Mark I Perceptron entre 1958 e 1960. Era uma máquina física:
- 400 fotorreceptores (matriz 20×20) capturavam imagens de 7×7 cm.
- 512 unidades de associação com pesos implementados como potenciômetros conectados a pequenos motores elétricos.
- 8 unidades de output.
- Treino: atualizações de peso eram literalmente motores girando os potenciômetros segundo o algoritmo.
A demonstração pública (NYU, 1958) classificou letras impressas e gerou uma manchete famosa do New York Times: “Navy Reveals Embryo of Computer Designed to Read and Grow Wiser”. O hype foi grande — Rosenblatt disse à imprensa que perceptrons logo seriam capazes de reconhecer pessoas, traduzir idiomas, e reproduzir-se.
A controvérsia de 1969
Marvin Minsky e Seymour Papert (MIT) publicaram em 1969 Perceptrons: An Introduction to Computational Geometry. O livro provou, formalmente, várias limitações:
- Perceptrons single-layer não conseguem aprender XOR (problema clássico não-linearmente separável).
- Não conseguem detectar paridade sem features pré-engenheiradas.
- Não conseguem decidir conectividade de uma figura sem rede arbitrariamente grande.
Esses resultados eram matematicamente corretos, mas o espírito do livro foi interpretado pela comunidade como “redes neurais são limitadas demais, não vale a pena pesquisar”. Financiamento ARPA migrou para IA simbólica. Rosenblatt morreu em 1971 num acidente de barco, aos 43 anos. O primeiro AI Winter neural começou.
O ponto-chave que o livro não enfatizou suficientemente: multi-layer perceptrons resolvem XOR. A limitação era da arquitetura single-layer, não da abordagem neural geral. Levou até Rumelhart, Hinton & Williams (1986) popularizarem Backpropagation para a comunidade aceitar que MLPs eram poderosos.
Por que importa
O perceptron é o ancestral direto de cada neurônio em cada rede moderna. Você abre PyTorch, declara nn.Linear(in_features=512, out_features=256) — isso é 256 perceptrons em paralelo, recebendo 512 inputs cada, sem a função de ativação ainda. Adicione nn.ReLU() e tem o perceptron contemporâneo (sem a função degrau, que tem gradiente zero quase em todo lugar — por isso não dá pra treinar com backprop sem suavização).
Define o paradigma supervisionado. Dados rotulados + função de loss + ajuste iterativo de parâmetros — esse template, hoje universal, foi instanciado primeiro pelo perceptron.
Ensina sobre AI Winters. A controvérsia de 1969 é estudo de caso obrigatório em ética e sociologia de IA. Resultados técnicos verdadeiros foram comunicados de forma que sufocou uma agenda de pesquisa por 15 anos. Em 2026, com debates parecidos rondando “scaling laws estão batendo no teto?” e “transformers são suficientes?”, o paralelo é constantemente invocado.
Demonstra o papel do hardware. O Mark I era um perceptron porque tinha 400 fotorreceptores físicos. Modelos modernos têm bilhões de parâmetros porque H100s e B200s existem. A relação entre capacidade computacional e progresso de IA é direta — sempre foi.
Estado em 2026
- Perceptron como unidade conceitual continua sendo introdução obrigatória em cursos de ML. Andrew Ng, Karpathy, Bishop, Goodfellow — todos começam por aqui.
- Cornell mantém um perceptron físico (não o Mark I original, infelizmente perdido) [VERIFICAR — Smithsonian tem peças do Mark I; Cornell tem documentação].
- Convergence theorem de Rosenblatt é base de prova para SVMs (Vapnik), passive-aggressive learning, e online learning em geral.
- Spiking neural networks (neuromorphic computing — Intel Loihi 2, IBM TrueNorth) revisitam perceptrons com timing realista de spikes, aproximando-se mais do cérebro biológico que Rosenblatt buscava modelar.
- A reabilitação histórica de Rosenblatt está em andamento. Por décadas ele foi visto como “o cara que prometeu demais”; hoje é visto como precursor injustiçado, ofuscado pela retórica de Minsky.
O perceptron na Magik LLM Gathering representa o átomo do aprendizado — pequeno, limitado, mas o building block do resto.
Tratamento de carta — proposta
The Perceptron Modelo · Classical ML · custo
1/1. Stat-fixo (não pode ser modificado).
Aprender: quando recebe dano não-letal, ganhe +0/+1 permanentemente (treino ajusta resiliência, não força).
“Um neurônio só. Mas o suficiente para começar a aprender.”
O custo mínimo, o stat-fixo e o pequeno crescimento por exposição refletem o perceptron literalmente: simples, linear, mas com regra de update que melhora com dados.
Veja também
Feito pela Magik LLM Gathering
Isto que você acabou de ler é o nosso trabalho.
A Magik LLM Gathering constrói produtos de IA de verdade — e escreve sobre eles em português, sem hype. Se quiser conversar sobre o seu, deixe seu contato.
Recebido. Vamos te escrever em breve.
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6).
- Rosenblatt, F. (1962). Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms.
- Minsky, M., Papert, S. (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press.
- Olazaran, M. (1996). A Sociological Study of the Official History of the Perceptrons Controversy. Social Studies of Science, 26(3).